Alternative title: Using the Azure Application Gateway to do content redirection with a storage account static website in a secure way.
I was looking at a scenario where I needed to find a platform method of setting up a website that would:
- Be cost-effective
- Be able to easily receive content directly from Azure virtual machines
- Be secure
This post will describe the solution.
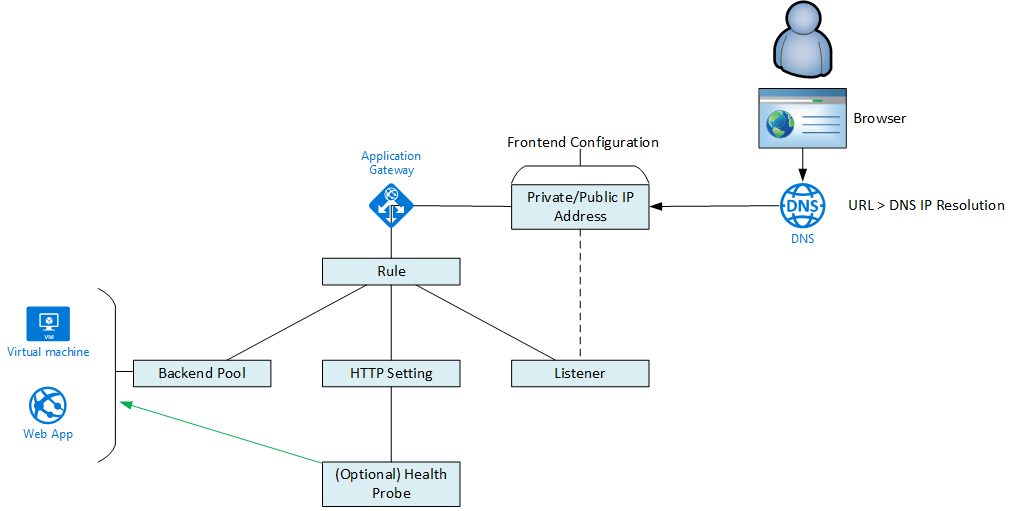
The Storage Account
A resilient storage account is set up with a static website. The content can be uploaded to the $web container. The firewall is enabled and only traffic from the virtual machine subnet and an Azure Application Gateway or Web Application Firewall subnet is allowed. This means that you get a 404 error when you try to access the website from any other address space.
The WAF
A WAFv2 is set up. The WAF subnet is protected by an NSG. The WAF is controlled by a WAF policy. And certificates for custom domains are stored in a Key Vault – the WAF uses a user-managed identity to get Get/List rights to secrets/certificates in the Key Vault’s access policy. A multi-site HTTPS Listener is set up for the static website using a custom domain name:
- The HTTP setting will handle the name translation from the custom domain name to the default storage account URI.
- The Key Vault will store the certificate for the custom domain name.
- There is full end-to-end encryption thanks to the storage account using a Microsoft-supplied certificate for the default storage account URI.
The HTTP setting in the WAF will be set up as follows:
- HTTPS
- Use Well-Known CA Certificate (Yes)
- Override with a new hostname: the default URI of the static website
Solution 1 – Service Endpoint
In this case, the WAF subnet has a Microsoft.Storage service endpoint enabled. This will mean that traffic from the WAF to the storage account hosting the static website will fall through a routing “trap door” across the Azure private backbone to reach the storage account. This keeps the traffic relatively private and reduces latency.

The backend pool of the WAF is the FQDN of the static website.
Pros:
- Easy to set up.
Cons:
- Service Endpoints appear to be a dead-end technology
- It will require the Microsoft.Storage Service Endpoint to be configured in every subnet that needs to interact with the website/storage account.
Solution 2 – Private Link/Private Endpoint
In this design, Service Endpoint is dropped and replaced with a Private Endpoint associated with the Web API of the storage account. This Private Endpoint can be in the same VNet as the WAF or even a different (peered) VNet to the WAF.
 The only change to the WAF configuration is that the backend pool must now be the private IP address of the Private Endpoint. Now traffic will route from the WAF subnet to the storage account subnet, even across peering connections.
The only change to the WAF configuration is that the backend pool must now be the private IP address of the Private Endpoint. Now traffic will route from the WAF subnet to the storage account subnet, even across peering connections.
Pros:
- Private Link/Private Endpoint is the future for this kind of connectivity.
- There is no need to configure subnets with anything – they just need to route to the storage account (to modify content) or the WAF (access content).
Cons:
- A little more complex to set up, but the effort is returned in the long-run with less configuration required.
There is no support for inbound NSG rules for the Private Endpoint but:
- That is coming in the future
- The storage account firewall is rejecting unwanted direct traffic
- The NSG in front of the WAF provides Layer-4 security and the WAF provides Layer-7 security
Want to Learn More?
Why not join me for an ONLINE 1-day training course on securing Azure IaaS and PaaS services. Securing Azure Services & Data Through Azure Networking is my newest Azure training course, designed to give Level 400 training to those who have been using Azure for a while. It dives deep on topics that most people misunderstand and covers many topics similar to the above content.