In this post, I’ll show how I solved a failure, that occurred during an Azure Image Builder (Packer) build with a Ubuntu 20.04 image, which resulted in a bunch of errors that contained E: Could not open file /var/lib/apt/lists/ with a bunch of different file names.
Disclaimer
I am Linux-disabled. I started my career programming on UNIX but switched to being a Microsoft infrastructure person a year later – and that was a long time ago. I am not a frequent Linux user but I do acknowledge its existence and usefulness. In other words, I figured out a fix for me, but it might not be a fix for you.
The Problem
I was using Azure Image Builder, which is based on Packer, to allow the regular creation of a Ubuntu 20.04 image with the latest updates and bits for acting as the foundation of a self-hosted DevOps agent VM Scale Set in a secure Azure network.
I had simple needs:
Install Unzip
Install Terraform
What makes it different is that I need the installations to be non-interactive. Windows has a great community with that kind of challenge. After a lot of searching, I realise that Linux does not.
I set up the tasks in the image template and for a month, everything was fine. Images built and rebuilt. A few days ago, a weird issue started where the first version of a template build was fine, but subsequent builds failed. When I looked at the build log, I saw a series of errors when apt (the package installed) ran that started with:
E: Could not open file /var/lib/apt/lists/…
The Solution
I tried a lot of things, including:
apt-get update
apt-get upgrade -y
But guess, what – the errors just moved.
I was at the end of my tether when I decided to try something else. The apt package installation for WinZip worked some of the time. What was wrong the rest of the time? Time – that was the key word.
Something needed more time before I ran any apt commands. I decided to embed a bunch of sleep commands to let things in Ubuntu catchup with my build process.
I have two tasks that run before I install Terraform. The first prepares Linux:
I’ve ran this code countless times yesterday and it worked perfectly. Sure, the sleeps slow things down, but this is a batch task that (outside of testing) I won’t be waiting on so I am not worried.
It is possible to dynamically retrieve the resulting IP address of an Azure Private Endpoint and use it in other resources in Terraform. This post will show you how.
Scenario
You are building some PaaS resources using Private Endpoints. You have no idea what the IP addresses are going to be. But you need to use those IP addresses elsewhere in your Terraform code, for example in an NSG rule. How do you get the IP addresses?
Find The Properties
The trick for this is to use the terraform state command. In my case, I deployed a Cosmos DB resource using azurerm_private_endpoint.cosmosdb-account1. To view the state of the resource, I can run:
terraform state show azurerm_private_endpoint.cosmosdb-account1
That outputs a bunch of code:
Terraform state of a Cosmos DB resource
You can think of the exposed state as a description of the resource the moment after it was deployed. Everything in that state is addressable. A common use might be to refer to the resource ID (azurerm_private_endpoint.cosmosdb-account1.id) or resource name (azurerm_private_endpoint.cosmosdb-account1.name) properties. But you can also get other properties that you don’t know in advance.
The Solution
Take another look at the above diagram. There is an array property called private_dns_zone_configs that has one item. We can address this property as azurerm_private_endpoint.cosmosdb-account1.private_dns_zone_configs[0].
In there there is another array property, with two items, called record_sets. There is one record set per IP address created for this private endpoint. We can address these properties as azurerm_private_endpoint.cosmosdb-account1.private_dns_zone_configs[0].record_sets[0] and azurerm_private_endpoint.cosmosdb-account1.private_dns_zone_configs[0].record_sets[1].
Cosmos DB creates a private endpoint with multiple different IP addresses. I deliberately chose Cosmos DB for this example because it shows a more complex probelm and solution, demonstrating a little bit more of the method.
Dig into record_sets and you’ll find an array property called ip_addresses with 1 item. If I want the two IP addresses of this private endpoint then I will use: azurerm_private_endpoint.cosmosdb-account1.private_dns_zone_configs[0].record_sets[0].ip_addresses[0] and azurerm_private_endpoint.cosmosdb-account1.private_dns_zone_configs[0].record_sets[1].ip_addresses[0].
Using the Addresses
destination_address_prefixes = [
azurerm_private_endpoint.cosmosdb-account1.private_dns_zone_configs[0].record_sets[0].ip_addresses[0], // Cosmos DB Private Endpoint IP 1
azurerm_private_endpoint.cosmosdb-account1.private_dns_zone_configs[0].record_sets[1].ip_addresses[0] // Cosmos DB Private Endpoint IP 2
]
}
And now I have code that will deploy an NSG rule with the correct destination IP address(es) of my private endpoint without knowing them. And even better, if something causes the IP address(es) to change, I can rerun my code without changing it, and the rules will automatically update.
In this post, I’m going to discuss the shock that switching from traditional CapEx spending to cloud/OpEx spending causes. I will discuss how to prepare yourself for what is to come, how to govern spending, and how to enforce restrictions.
The Switch
Most of you who will read this article have been working in IT for a while, that is, you are not a “cloud baby” (born in the cloud). You’ve likely been involved with the entire lifecycle of systems in organisations. You’ve specified some hardware, gone through a pricing/purchase process, owned that hardware, and replaced it 3-10 years later in a cyclical process. It’s really only during the pricing/purchase process which happens only every 3-10 years in the life of a system, that you have cared about pricing. The accountants cared – they cared a lot about saving money and doing tax write-offs. But once that capital expenditure (CapEx) was done, you forgot all about the money. And you’re in IT so you don’t care about the cost of electricity, water, floorspace, or all the other things that are taken care of by some other department such as Facilities.
Things are very different in The Cloud. Here, we get a reminder every month about the cost of doing business. Azure sends out an invoice and someone has gotta pay the piper. Cloud systems run on a “use it and pay for it” model, just like utilities such as electricity. The more you use, the more you pay. Conversely, the less you use, the less you pay.
Sticker Shock
Have you ever wandered around a shop, seen something you liked, had a look at the price tag and felt a shocked at the high price? That’s how the person who signs the checks in your organisation starts to feel every month after your first build in or migration into Azure. Before an organisation starts up in The Cloud, their fears are about security, compliance, migration deadlines, and so on. But after the first system goes live, the attention of the business is on the cost of The Cloud.
There is a myth that The Cloud is cheaper. Sometimes, yes, but not always – large virtual machines and wasteful resource sizing stand out. In CapEx-based IT, you paid for hardware and software. Someone else in the business paid for all the other stuff that made the data centre or computer room possible. In The Cloud, the cost includes all those aspects, and you get the bill every month. This is why cost management becomes a number 1 concern for Cloud customers.
I have seen the effect of sticker shock on an organisation. In one project that I was a lead on, the CTO questioned every cost soon after the bills started to arrive. The organisation was a non-profit and cash flow was intended for their needy clients. Every time something was needed to enable one of their workloads, the justification for the deployment was questioned.
In other scenarios, the necessary (for agility) self-service capability of The Cloud provides developers and operators with a spigot through which cash can leave the organisation. I heard a story when I started working with Azure about a developer that wrote a bad Azure SQL query and left it to run over a long weekend. The IT department came in the following week to find three years of Azure budget spent in a few days.
Dec, Ops, And … Fin?
You’ve probably heard of DevOps, the mythical bringing together of eternal enemies, Developers and IT Operations. DevOps hopes to break down barriers and enable aligned agility that provides services to the business.
Now that we’ve all been successful at implementing DevOps (right?!?!) it’s time to forge those polar IT opposites with the folks in finance.
Finance needs to play a role:
Early in your cloud journey
During the lifecycle of each workload
The Cloud Journey
The process that an organisation goes through while adopting The Cloud is often called a cloud journey. Mid-large organisations should look at the Cloud Adoption Framework (a CAF exists for Azure, AWS, and Google Cloud) because of the structure that it provides to the cloud journey. Smaller organisations should take some inspiration from CAF – a lot of the concepts will be irrelevant.
A critical early step in a CAF is to work with the people that will be signing the cheques. The accountants need to learn:
Developers and operators will be free to deploy anything they want, within the constraints of organisation-implemented governance.
How the billing process is going to change to a monthly schedule based on past usage.
About the possibilities of monitoring and alerting on consumption.
The Lifecycle of Each Workload
In DevOps, Developers and Operators work together to design & operate the code and resources together, instead of the historical approach where square code is written and Ops try to squeeze it into round resources.
When we bring Finance into the equation, the prediction of cost and the management of cost should be designed with the workload and not be something that is tacked on later.
Architects must be aware that resource selection impacts costs. Picking a vCore Azure SQL database instead of a lower-cost DTU SKU “just to be safe” is safe from a technical perspective but can cost 1000% more. Designing an elastic army of ants, based on small compute instances that auto-scale while maintaining state, provides a system where the cost is a predictable percentage of revenue. Reserved instances and licensing to use hybrid use benefit can reduce costs of several resource types (not just virtual machines) over one-to-three years.
A method of associating resources with workloads/projects/billing codes must be created. The typical method that is discussed is to use tagging – which, despite all the talk of Azure Policy – requires a human to apply values to the tags which may be deployed automatically. I prefer a different approach, using one subscription per workload and using that natural billing boundary to do the work for me.
The tool for managing cost is perfectly named: Azure Cost Management. Cost Management is not perfect – I seriously dislike how some features do not work with CSP offers – but the core features are essential. You can select any scope (tag, subscription, or resource group) and get an analysis of costs for that scope in many different dimensions, including a prediction for the final cost at the end of the billing period. A feature that I think is essential for each workload is a budget. You can use cost analysis to determine what the spend of a workload will be, and then create alerts that will trigger based on current spending and forecasted spending. Those alerts should be sent to the folks that own the workload and pay the bill – enabling them to crack some fingers should the agreed budget be broken.
Source: Microsoft
Wrap Up
Once the decision to go to The Cloud is made, there is a rush to get things moving. Afterward, there’s a panic when the bills start to come in. Sticker shock is not a necessity. Take the time to put cost management into the process. Bring the finance people and the workload owners into the process and educate them. Learn how resources are billed for and make careful resource and SKU selections. Use Azure Cost Management to track costs and generate alerts when budgets will be exceeded. You can take control, but control must be created.
An unfortunately common scenario is where you must create a site-to-site network connection with a third-party network from your Azure network using NAT. This post will explain a few solutions.
The Scenario
There are those out there who think that every implementation in The Cloud is 100% under your control and is cloud-ready. But sometimes, you must fit in with other people’s designs and you can’t use cool integrations such as Private Link or API. Sometimes you need to connect your network to a third party and they dictate the terms of the connection.
The connection is typically a site-to-site connection, usually VPN but I have seen ExpressRoute used. VPN means there are messy bits – you can control that with your own on-premises firewalls but you have no control over the VPN configuration of an externally owned firewall.
Site-to-site connections with a service provider means that there could be IP address overlap. The only way to handle that is to use NAT – and that is not always possible natively in the platform or it’s really badly documented.
Solution 1: On-Premises Relay
In this scenario, the third-party will make a connection to your on-premises network. NAT is implemented on the on-premises network to translate your private Azure address to some “public address” (it is routed only over the private connections).
The connection between on-premises and Azure could be VPN or ExpressRoute.
This design is useful in two situations:
You are using ExpressRoute – the ExpressRoute Gateway does not offer NAT functionality.
The third-party insists that you use some kind of VPN configuration that is not supported in Azure, for example, GRE.
The downside with this design is that might be additional latency between the third-party and your Azure network.
Solution 2: AWS Relay
Oh – did this post by an Azure MVP just mention AWS? Sure – there is a time and a place for everything.
This solution is similar to the on-premises relay solution but it replaces on-premises with AWS. This can be useful where:
You want to minimise on-premises resources. AWS does support GRE so a VPN connection to a third-party that requires GRE can be handled in this way.
You can use an AWS region that is close to either the third-party and/or your Azure region and minimise latency.
Note that the connection from AWS or Azure could be either VPN or ExpressRoute (with an ISP that supports Azure ExpressRoute and AWS Direct Connect).
The downside is that there is still “more stuff” and a requirement for skills that you might not have. On the plus side, it offers compatibility with reduced latency.
Solution 3: Azure Relay
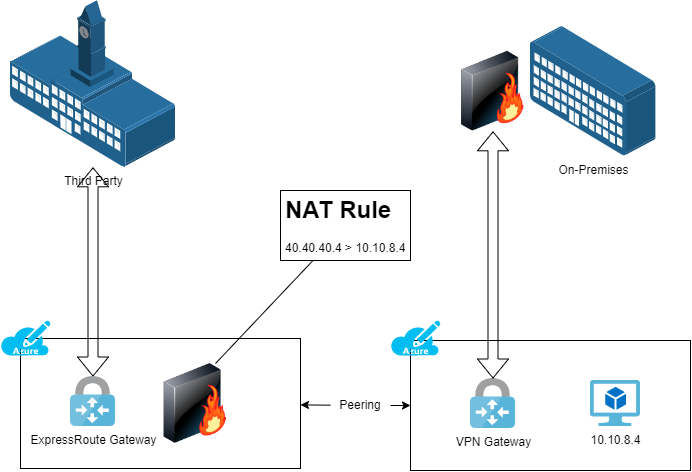
In this design, the third-party makes a connection to your Azure network(s) using ExpressRoute. But as usual, you must implement a NAT rule. The ExpressRoute Gateway cannot natively implement NAT. That requires that you must deploy “an appliance” (NVA or Linux VM with NAT tables).
In the above design, there is a route table associated with the GatewaySubnet of the ExpressRoute Gateway. An user-defined route with a prefix of 40.40.40.4 will forward to the appliance as the next hop. A user-defined route on the VM’s subnet with a prefix of the third-party network(s) will use the appliance as the next hop.
This design allows you to use ExpressRoute to connect to the third-party but it also allow you to implement NAT.
Solution 4: VPN Gateway & NAT
Other than using some modern solution, such as authenticated API over HTTPS, this is probably “the best” scenario in terms of Azure resource simplicity.
The third-party connects to your Azure network using a site-to-site VPN. The connection is terminated in Azure using a VPN Gateway. The Azure VPN Gateway is capable of supporting NAT rules. Unfortunately, that’s where things begin to fall apart because of the documentation (quality and completeness).
This is a simple scenario where the third-party needs access to an IP address (VM other otherwise) hosted in your Azure network. That internal address of your Azure resource must be translated to a different External IP Address.
As long as your VPN Gateway is VpnGw2/VpnGw2Az or higher, then you can create NAT rules in the Gateway. The scenario that I have described requires a confusingly-named egress NAT rule – you are translating an internal IP address(es) to an external IP address(es) to abstract the internal address(es) for ingress traffic. An ingress NAT rule translates an external IP address(es) to an internal address(es) to abstract the external address(es) for ingress traffic.
The Terraform code for my scenario is shown below: I want to make my Azure resource with 10.10.8.4 available externally as 40.40.40.4 on TCP 443:
Once you have the NAT rule, you will associate it with the Connection resource for the VPN.
And that’s it – 10.10.8.4 will be available as 40.40.40.4 on TCP 443 to the third-party – no other connection can use this NAT rule unless it is associated with it.
Solution 5 – NVA & NAT
This is alm ost the same as the previous example, but an NVA is used instead of the Azure VPN Gateway, maybe because you like their P2S VPN solution or you are using SD-WAN. The NAT rules are implemented in the NVA.
This post will show you how to get the ARM (also for Bicep, Terraform, etc) names of the diagnostics logs for an Azure resource.
Problem
When you are deploying Azure resources as code, you might need to enable diagnostics logs. This might require you to know the name of each log. Here’s the issue: the names of the logs in the Azure Portal are usually different from the names that are used in the code. Sure, they’ll remove the spaces and use camel-case, but that’s predictable. Often, the logs have completely different names.
Sometimes the names are documented – thank you App Services! Sometimes you cannot find the log names – boo Azure SQL!
Solution
The tip that I’m going to share is useful – this is the second time in a few weeks that I’ve used this approach.
If you know what you are looking for, diagnostics logs in this case, then do a search online for something like “Azure Diagnostics Settings REST API”. This will bring you to a Microsoft page that shares different methods for the API.
I wanted to see what the log names are for an Azure SQL Database. So I manually created the diagnostic setting. After that, grab the resource ID of the Azure SQL Database.
Then I did the above search. I clicked the Get method and then clicked the Try It button. Put the name of the diagnostic setting (that you created) in name. Put the resource ID of the Azure SQL Database in resourceID. And then click Run. A second later, the ARM for the diagnostic setting is presented on a screen below, including all the diagnostics log names.
This article will explain how to simply import a resource that was successfully deployed by Terraform from a GitHub action or DevOps pipeline that timed out into your state file.
Background
I’m working a lot with Terraform these days. ARM doesn’t scale, and while I’d prefer to use a native toolset such as Bicep, it is just a prettier ARM and has most of the same issues – scale (big architectures) and support (Azure AD = helloooo!).
The Scenario
You are writing Terraform to deploy resources in Microsoft Azure. That code is run by a DevOps pipeline or a GitHub action. You add a resource such as App Service Environment v3 or Azure SQL Managed Instance that can take hours to deploy. A DevOps pipeline will timeout after 1 hour.
As expected, the pipeline times out but the resource deploys. You try to run the pipeline again but pipeline will fail because you have resources that don’t exist in the state file. Ouch! You do your due diligence and search, and you find nothing but noise, and that does not help you. That was my experience, anyway!
State File Lock
I use blob storage in secured Azure Storage Accounts to store state files. The timed-out pipeline locked the state file using a blob lease. Browse to the container, select the blob and release the lock.
The Fix
The fix is actually pretty simple. You’ve already done most of the work – defining the resource.
In my example, I have a file called ase.tf. I have a resource definition that goes something like this:
I made a copy of my pipeline file. Then I modified my pipeline yaml file so it would run a terraform import command instead of a terraform apply.
terraform import azurerm_app_service_environment_v3.ase /subscriptions/<subscription id>/resourceGroups/<resource group name>/providers/Microsoft.Web/hostingEnvironments<resource name>
I used the Get–AzAppServiceEnvironment cmdlet in Cloud Shell to retrieve the resource ID of the ASE because it wasn’t shared in the Azure Portal.
I re-ran the pipeline and the state file was updated with the resource. Reset the pipeline file back to the way it was (back to terraform apply) and your pipeline should run clean.
This post explains how to unlock a subnet when you have deleted an App Service/Function App with Regional VNet Integration.
Here I will describe how you can deal with an issue where you cannot delete a subnet from a VNet after deleting an Azure App Service or Function App with Regional VNet Integration.
Scenario
You have an Azure App Service or Function App that has Regional VNet Integration enabled to connect the PaaS resource to a subnet. You are doing some cleanup or redeployment work and want to remove the PaaS resources and the subnet. You delete the PaaS resources and then find that you cannot:
Delete the subnet
Disable subnet integration for Microsoft.Web/serverFarms
The error looks something like this:
Failed to delete resource group workload-network: Deletion of resource group ‘workload-network’ failed as resources with identifiers ‘Microsoft.Network/virtualNetworks/workload-network-vnet’ could not be deleted. The provisioning state of the resource group will be rolled back. The tracking Id is ‘iusyfiusdyfs’. Please check audit logs for more details. (Code: ResourceGroupDeletionBlocked) Subnet IntegrationSubnet is in use by /subscriptions/sdfsdf-sdfsdfsd-sdfsdfsdfsd-sdfs/resourceGroups/workload-network/providers/Microsoft.Network/virtualNetworks/workload-network-vnet/subnets/IntegrationSubnet/serviceAssociationLinks/AppServiceLink and cannot be deleted. In order to delete the subnet, delete all the resources within the subnet. See aka.ms/deletesubnet. (Code: InUseSubnetCannotBeDeleted, Target: /subscriptions/sdfsdf-sdfsdfsd-sdfsdfsdfsd-sdfs/resourceGroups/workload-network/providers/Microsoft.Network/virtualNetworks/workload-network-vnet)
It turns out that deleting the PaaS resource leaves you in a situation where you cannot disable the integration. You have lost permission to access the platform mechanism.
In my situation, Regional VNet integration was not cleanly disabling so I did the next logical thing (in a non-production environment): started to delete resources, which I could quickly redeploy using IaC … but I couldn’t because the subnet was effectively locked.
Solutions
There are 2 solutions:
Call support.
Recreate the PaaS resources
Option 1 is a last resort because that’s days of pain – being frankly honest. That leaves you with Option 2. Recreate the PaaS resources exactly as they were before with Regional VNet Integration Enabled. Then disable the integration (go into the PaaS resource, go into Networking, and disconnect the integration).
That process cleans things up and now you can disable the Microsoft.Web/serverFarms delegation and/or delete the subnet.
I will explain a recent situation where an application that uses SignalR/WebSockets disconnected when routed through the Azure Application Gateway during listener configuration changes.
Background
Me and my team are working with a client, migrating their on-premises workloads to Microsoft Azure. Some of the workloads are built using SignalR which provides optimal communication for in-sequence data over WebSockets. The users of the applications expect a reliable stream of data over a long period of time.
Our design features an Azure Application Gateway with the Web Application Firewall. The public DNS records for the applications point to the AppGw, which inspects the traffic and proxies to the backend pools which host the applications.
As one can imagine, there has been a lot of testing, debugging, and improvement. That means there have been many configuration changes to the application configurations in the AppGw: listeners, HTTP settings, and backend pools.
The Problem
We had stable connections from test clients to the applications but the developers saw something. Every now, and then, all clients would lose their connection. The developers observed the times and noticed a correlation with when we ran our DevOps pipelines to apply changes. In short: every time we updated the AppGw, the clients were disconnected.
I reached out to Microsoft (thank you to Ashutosh who was very helpful!). Ashutosh dug into the platform logs and explained the issue to me.
The WebSocket sessions were handled by the “data plane” of the AppGw data resource. Every time a new configuration is applied, a new data plane is created. The old data plane is maintained for a short period of time – 30 seconds by default – before being dropped. That means when we applied a change, the handling for existing WebSocket connections was dropped 30 seconds later.
The solution we have come up with is to isolate the “production” workloads into a stable WAF while unstable workloads are migrated to a “pre-staging” WAF. Any changes to the “production” WAF must be done out of hours unless there is an emergency that demands a change and we acknowledge that disconnects will happen.
Here’s all the news that I thought was interesting for Ops and Security folks working with Azure IaaS from December 2022.
Azure VMware Solution
Azure VMware Solution Advanced Monitoring: This solution add-on deploys a virtual machine running Telegraf in Azure with a managed identity that has contributor and metrics publisher access to the Azure VMware Solution private cloud object. Telegraf then connects to vCenter Server and NSX-T Manager via API and provides responses to API metric requests from the Azure portal.
Azure Kubernetes Service
Microsoft and Isovalent partner to bring next generation eBPF dataplane for cloud-native applications in Azure: Microsoft announces the strategic partnership with Isovalent to bring Cilium’s eBPF-powered networking data plane and enhanced features for Kubernetes and cloud-native infrastructure. Azure Kubernetes Services (AKS) will now be deployed with Cilium open-source data plane and natively integrated with Azure Container Networking Interface (CNI). Microsoft and Isovalent will enable Isovalent Cilium Enterprise as a Kubernetes container App offering onto Azure Container Marketplace. This will provide a one-click deployment solution to Azure Kubernetes clusters with Isovalent Cilium Enterprise advanced features.
Generally Available: Kubernetes 1.25 support in AKS: AKS support for Kubernetes release 1.25 is now generally available. Kubernetes 1.25 delivers 40 enhancements. This release includes new changes such as the removal of PodSecurityPolicy.
Azure Backup
General Availability of Cross Zonal Restore of Azure Virtual Machines from Azure Backup: With the preview of Cross Zonal Restore of Azure VMs, Azure Backup offers a compelling set of durability options for your backup data including ZRS for intra-region high durability. Aidan’s note – you should consider this with regions such as Norway East where the paired region is unavailable to 99.9% of customers.
Announcing the Public Preview of AVD Insights at Scale: This update provides the ability to review performance and diagnostic information across multiple host pools in one view. Aidan’s note – no additional diagnostics settings are required.
Announcing general availability of RDP Shortpath: RDP Shortpath improves the transport reliability of Azure Virtual Desktop connections by establishing a direct UDP data flow between the Remote Desktop client and session hosts. This feature is enabled by default for all customers. Aidan’s Note – I haven’t looked into this but there may be networking issues where firewall’s/routing are deployed.
Public preview: New Memory Optimized VM sizes – E96bsv5 and E112ibsv5: The new E96bsv5 and E112ibsv5 VM sizes part of the Azure Ebsv5 VM series offer the highest remote storage performances of any Azure VMs to date. The new VMs can now achieve even higher VM-to-disk throughput and IOPS performance with up to 8,000 MBps and 260,000 IOPS.
Generally Available: Azure Dedicated Host – Restart: Azure Dedicated Host gives you more control over the hosts you deployed by giving you the option to restart any host. When undergoing a restart, the host and its associated VMs will restart while staying on the same underlying physical hardware.
Governance
Public preview: Use tag inheritance for cost management: You no longer need to ensure that every resource is tagged or rely on resource providers to support and emit tags in their billing pipeline for cost management. Aidan’s Note – Restricted to EA/MCA … which unreasonably sucks. The latest example of “cost management” excluding other customers.
Public preview: Azure NetApp Files cross-zone replication: The cross-zone replication feature allows you to replicate your Azure NetApp Files volumes asynchronously from one Azure availability zone (AZ) to another in the same region.
Azure Site Recovery
Public Preview: Azure Site Recovery Higher Churn Support: Azure Site Recovery (ASR) has increased its data churn limit by approximately 2.5x to 50 MB/s per disk. With this, you can configure disaster recovery (DR) for Azure VMs having data churn up to 100 MB/s. This helps you to enable DR for more IO intensive workloads.
Networking
General availability: Feature enhancements to Azure Web Application Firewall (WAF): Azure’s global Web Application Firewall (WAF) running on Azure Front Door, and Azure’s regional WAF running on Application Gateway, now support additional features that help organizations improve their security posture and make it easier to manage logging across resources.
Miscellaneous
Public Preview : Introducing Multi-Region Replication for Azure Key Vault Managed HSM: The feature allows you to extend a managed HSM pool from one Azure region to an other thereby enhancing the availability of mission critical cryptographic keys with automated key replication and maximizing read throughput and latency with the closest available region.
That heading is a positive way to get your holiday spirit going, eh? I’m afraid I’m going to be your Festive Tech Calendar 2022 Grinch and rain doom and gloom on you for the next while. But hang on – The Grinch story ends with a happy-ever-after.
In this article, I want to explain why a typical “Azure migration” project is doomed to fail to deliver what the business ultimately expects: an agile environment that delivers on the promises of The Cloud. The customers that are affected are typically larger: those with IT operations and one or more development teams that create software for the organisation. If you don’t fall into that market, then keep reading because this might still be interesting to you.
My experience is Microsoft-focused, but the tale that I will tell is just as applicable to AWS, GCP, and other alternatives to Microsoft Azure.
Migration Versus Adoption
I have been working with mid-large organisations entering The Cloud for the last 4 years. The vast majority of these projects start with the same objectives:
Migrate existing workloads into Azure, usually targeting migration to virtual machines because of timelines and complexities with legacy or vendor-supplied software.
Build new workloads and, maybe, rearchitect some migrated workloads.
Those two objectives are two different projects:
Migration: Get started in Azure and migrate the old stuff
Adoption: Start to use Azure to build new things
Getting Started
The Azure journey typically starts in the IT Operations department. The manager that runs infrastructure architecture/operations will kick off the project either in-house or with a consulting firm. Depending on who is running things, there will be some kind of process to figure out how to prepare the landing zone(s) (the infrastructure) in Azure, some form of workloads assessment will be performed, and existing workloads will be migrated to The Cloud. That project, absent of (typically organisation) issues, should end well:
The Azure platform is secure and stable
The old workloads are running well in their landing zone(s)
The Migration project is over, there is a party, people are happy, and things are … great?
Adoption Failure
Adoption starts after Migration ends. Operations has built their field of dreams and now the developers will come – cars laden with Visual Studio, containers, code, and company aspirations will be lining up through the corn fields of The Cloud, eager to get going … or not. In reality, if Migration has happened like I wrote above, things have already gone wrong and it is already probably too late to change the path forward. That’s been my experience. It might take 1 or 2 years, but eventually, there will be a meeting where someone will ask: why do the developers not want to use Azure?
The first case of this that I saw happened with a large multinational. Two years after we succeeded with a successful Azure deployment – the customer was very happy at the time – we were approached by another department, the developers, in the company. They loved what we built in Azure but they hated how it was run by IT. IT had taken all their ITIL processes, ticketing systems, and centralised control that were used for on-premises and applied them to what we delivered in Azure. The developers were keen to use agile techniques, tools, and resource types in Azure, but found that the legacy operations prevented this from working. They knew who built the Azure environment, they came to us, and asked us to build a shadow IT environment in Azure just for them, outside of the control of IT Operations!
That sounds crazy, right? But this is not a unique story. We’ve seen it again and again. I hear stories of “can we create custom roles to lock down what developers can do?” and then that adoption is failing. Or “developers find it easier to work elsewhere”. What has gone wrong?
Take a Drink!
Adoption is when the developers adopt what is delivered in Azure and start to build and innovate. They expect to find a self-service environment that enables cool things like GitOps, Kubernetes, and all those nerdy cool things that will make their job easier. But their adoption will not happen because they do not get that. They get a locked-down environment where permissions are restricted, access to platform resources might be banned because Operations only know & support Windows, and the ability to create firewall rules for Internet access or to get a VM is hidden behind a ticketing system with a 5-day turnaround.
Some of us in the community joke about taking a drink every time some Microsoft presenter says a certain phrase at a conference. One of those phrases in the early days of Microsoft Azure was “cloud is not where you work, it is how you work”. That phrase started reappearing in Microsoft events earlier this year. And it’s a phrase that I have been using regularly for nearly 18 months.
The problem that these organisations have is that they didn’t understand that how IT is delivered needs to change in order to provide the organisation with the agile platform that the Cloud can be. The Cloud is not magically agile; it requires that you:
Use the right tools & technology, which involves skills acquisition/development
People are reorganised
New processes are implemented
Let’s turn that into the Cloud Equation:
Cloud = Process(People + Tools)
Aidan Finn, failed mathematician and self-admitted cloud Grinch
With the current skills shortage, one might think that the tools/tech/skills part is the hard part of the Cloud Equation. Yes; developing or acquiring skills is not easy. But, that is actually the easiest part of the Cloud Equation.
Our business has had a split that has been there since the days of the first computer. It is worse than Linux versus Windows. It is worse than Microsoft versus Apple. It is worse than ex-Twitter employees versus Elon. The split that I talk of is developers (Devs) versus operations (Ops). I’ve been there. I have been the Ba*tard Operator From Hell – I took great joy in making the life of a developer miserable so that “my” systems were stable and secure (what I mistakenly viewed as my priority). I know that I was not unique – I see it still happens in lots of organisations.
People must be reorganised to work together, plan together, build and secure together, to improve workloads together … together. Enabling that “together” requires that old processes are cast aside with the physical data centre, and new processes that are suitable for The Cloud are used.
Why can’t all this be done after Migration has been completed? I can tell you that for these organisations, the failure happened a long time before Migration started.
The Root Cause
According to my article, who initiated the cloud journey? It was a manager in IT Operations. Who owns the old processes? The manager in IT Operations. Who is not responsible for the developers? The manager in IT Operations. Who is not empowered, and maybe not motivated, to make the required Tools(People + Process) changes that can enable an agile Cloud.
In my experience, a cloud journey project will fail at the Adoption phase if the entire journey does not start at the board level. Someone in the C-suite needs to kick that project off – and remain involved.
A Solution
Microsoft Cloud Adoption Framework 2022
The Microsoft Cloud Adoption Framework (AKA CAF and AWS and GCP have their own versions) recognises that Cloud Journey must start at the top. The first thing that should be done is to sit down with organisation leadership to discuss and document business motivations. The results of the conversation(s) should result in:
A documented cloud strategy plan
A clear communication to the business: this is how things will be with the implied “or else”
Only the CEO, CTO (or equivalent) can give the order that Operations and Development must change how things are done DevOps. Ideally, Security is put into that mix considering all the threats out there and that Security should be a business priority: DevSecOps. Only when all this is documented and clearly communicated, should the rest of the process start.
The Plan Phase of the CAF has some important deliverables:
Initial organisation alignment: Organise staff with their new roles in DevSecOps – The People part of the Cloud Equation.
Skills Readiness: Create the skills for the Tools part of the Cloud Equation.
Engineering starts in the Ready phase; this is when things get turned on and the techies (should) start to enjoy the project. The very first phase in the recently updated CAF is the Operating Model; this is a slight change that recognises the need for process change. This is when the final part of the Cloud Equation can be implemented: the new processes multiply the effect of tools/skills and organisation. With that in place, we should be ready, as a unified organisation, to build things for the organisation – not for IT Operations or the Developers – with agility and security.
I have skipped over all the governance, management, compliance, and finance stuff that should also happen to highlight the necessary changes that are usually missing.
Whether the teams are real or virtual, in the org chart or not, each workload will have a team made up of operations, security, and development skills. That team will share a single backlog that starts out with a mission statement or epic that will have a user story that says something like “the company requires something that does XYZ”. The team will work together to build out that backlog with features and tasks (swap in whatever agile terminology you want) as the project progresses to plan out tasks across all the required skill sets in the team and with external providers. This working together means that there are no surprises, Devs aren’t “dumping” code on IT, IT isn’t locking down Devs, and Security is built-in and not a hope-for-the-best afterthought.
Final Thoughts
The problem I have described is not unique. I have seen it repeatedly and it has happened and is happening all around the world. The fix is there. I am not saying that it is easy. Getting access to the C-Level is hard for various reasons. Changing momentum that has been there for decades is a monumental mission. Even when everyone is aligned, the change will be hard and take time to get right but it will be rewarding. Bon, voyage!